
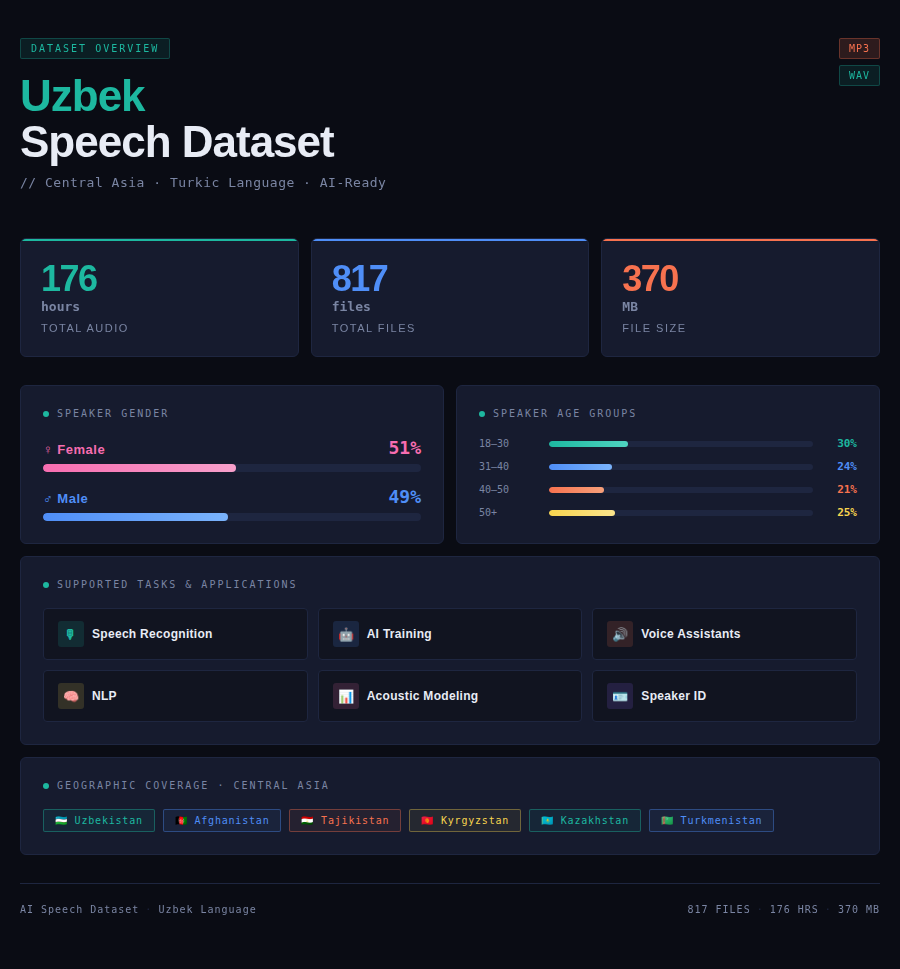
The Uzbek Speech Dataset provides an extensive repository of authentic audio recordings from native Uzbek speakers across Uzbekistan, Afghanistan, Tajikistan, Kyrgyzstan, Kazakhstan, and Turkmenistan. This specialized linguistic resource contains 176 hours of professionally recorded Uzbek speech accurately annotated for sophisticated machine learning tasks.
Uzbek, a Turkic language spoken by over 34 million people across Central Asia, is documented with phonetic characteristics essential for building effective speech recognition systems.
Dataset General Info
| Parameter | Details |
|---|---|
| Size | 176 hours |
| Format | MP3/WAV |
| Tasks | Speech recognition, AI training, voice assistant development, natural language processing, acoustic modeling, speaker identification |
| File size | 370 MB |
| Number of files | 817 files |
| Gender of speakers | Female: 51%, Male: 49% |
| Age of speakers | 18-30 years: 30%, 31-40 years: 24%, 40-50 years: 21%, 50+ years: 25% |
| Countries | Uzbekistan, Afghanistan, Tajikistan, Kyrgyzstan, Kazakhstan, Turkmenistan |
Use Cases
Central Asian Regional Integration
Organizations working across Central Asia can utilize the Uzbek Speech Dataset to develop regional communication platforms, cross-border trade systems, and Central Asian cooperation tools. Voice interfaces in Uzbek support regional integration initiatives, facilitate commerce across multiple countries, strengthen linguistic connections among Central Asian nations, and enable collaboration in education, trade, and cultural exchange. Applications include regional e-commerce platforms, cross-border logistics systems, and Central Asian cooperation portals
Agricultural Technology and Rural Development
Uzbekistan’s significant agricultural sector can leverage this dataset to create voice-based farming advisory systems, cotton cultivation guidance, and rural development platforms. Voice technology delivers agricultural information to Uzbek-speaking farmers, supports modernization of agricultural practices, enables market access for rural populations, and facilitates knowledge sharing about irrigation, crop management, and sustainable farming. Applications include weather forecasting services, crop disease identification, market price information, and agricultural extension services.
Tourism and Silk Road Heritage
Uzbekistan’s growing tourism industry can employ this dataset to develop voice-guided tours for Silk Road sites, cultural heritage applications, and tourism information systems. Voice technology enhances visitor experiences at Samarkand, Bukhara, and Khiva while promoting Uzbek language, supports tourism sector growth, enables multilingual heritage interpretation, and creates immersive experiences at historical monuments. Applications include virtual museum guides, archaeological site tours, and hospitality service platforms.
FAQ
Q: What is included in the Uzbek Speech Dataset?
A: The dataset includes 176 hours of audio from Uzbek speakers across Uzbekistan, Afghanistan, and Central Asian region. Contains 817 files in MP3/WAV format totaling 370 MB.
Q: Why is Uzbek important for Central Asia?
A: Uzbek is spoken by over 34 million people across multiple countries and is Central Asia’s most widely spoken Turkic language. Speech technology enables regional integration, supports cross-border commerce, and serves significant Central Asian population.
Q: How diverse is the speaker demographic?
A: Dataset features 51% female and 49% male speakers with ages: 30% (18-30), 24% (31-40), 21% (40-50), 25% (50+).
Q: What applications benefit from Uzbek technology?
A: Applications include regional trade platforms, agricultural advisory systems, tourism applications for Silk Road heritage sites, educational technology, and cross-border services connecting Central Asian Uzbek-speaking communities.
How to Use the Speech Dataset
Step 1: Dataset Acquisition
Download the dataset package from the provided link. Upon purchase, you will receive access credentials and download instructions via email. The dataset is delivered as a compressed archive file containing all audio files, transcriptions, and metadata. Ensure you have sufficient storage space for the complete dataset before beginning the download process. The package includes comprehensive documentation, sample code, and integration guides to help you get started quickly.
Step 2: Extract and Organize
Extract the downloaded archive to your local storage or cloud environment using standard decompression tools. The dataset follows a structured folder organization with separate directories for audio files, transcriptions, metadata, and documentation. Review the README file for detailed information about file structure, naming conventions, and data organization. Familiarize yourself with the metadata files which contain speaker demographics, recording conditions, and quality metrics essential for effective data utilization.
Step 3: Environment Setup
Install required dependencies for your chosen ML framework such as TensorFlow, PyTorch, Kaldi, or others according to your project requirements. Ensure you have necessary audio processing libraries installed including librosa for audio analysis, soundfile for file I/O, pydub for audio manipulation, and scipy for signal processing. Set up your Python environment with the provided requirements.txt file for seamless integration. Configure GPU support if available to accelerate training processes. Verify all installations by running the provided test scripts.
Step 4: Data Preprocessing
Load the audio files using the provided sample scripts which demonstrate best practices for data handling. Apply necessary preprocessing steps such as resampling to consistent sample rates, normalization to standard amplitude ranges, and feature extraction including MFCCs (Mel-frequency cepstral coefficients), spectrograms, or mel-frequency features depending on your model architecture. Use the included metadata to filter and organize data based on speaker demographics, recording quality scores, or other criteria relevant to your specific application. Consider data augmentation techniques such as time stretching, pitch shifting, or adding background noise to improve model robustness.
Step 5: Model Training
Split the dataset into training, validation, and test sets using the provided speaker-independent split recommendations to avoid data leakage and ensure proper model evaluation. Typical splits are 70-15-15 or 80-10-10 depending on dataset size. Configure your model architecture for the specific task whether speech recognition, speaker identification, emotion detection, or other applications. Select appropriate hyperparameters including learning rate, batch size, and number of epochs. Train your model using the transcriptions and audio pairs, monitoring performance metrics on the validation set. Implement early stopping to prevent overfitting. Use learning rate scheduling and regularization techniques as needed. Save model checkpoints regularly during training.
Step 6: Evaluation and Fine-tuning
Evaluate model performance on the held-out test set using standard metrics such as Word Error Rate (WER) for speech recognition, accuracy for classification tasks, or F1 scores for more nuanced evaluations. Analyze errors systematically by examining confusion matrices, identifying problematic phonemes or words, and understanding failure patterns. Iterate on model architecture, hyperparameters, or preprocessing steps based on evaluation results. Use the diverse speaker demographics in the dataset to assess model fairness and performance across different demographic groups including age, gender, and regional variations. Conduct ablation studies to understand which components contribute most to performance. Fine-tune on specific subsets if targeting particular use cases.
Step 7: Deployment
Once satisfactory performance is achieved, export your trained model to appropriate format for deployment such as ONNX, TensorFlow Lite, or PyTorch Mobile depending on target platform. Optimize model for inference through techniques like quantization, pruning, or knowledge distillation to reduce size and improve speed. Integrate the model into your application or service infrastructure whether cloud-based API, edge device, or mobile application. Implement proper error handling, logging, and monitoring systems. Set up A/B testing framework to compare model versions. Continue monitoring real-world performance through user feedback and automated metrics. Use the dataset for ongoing model updates, periodic retraining, and improvements as you gather production data and identify areas for enhancement. Establish MLOps practices for continuous model improvement and deployment.
For detailed code examples, integration guides, API documentation, troubleshooting tips, and best practices, refer to the comprehensive documentation included with the dataset. Technical support is available to assist with implementation questions and optimization strategies.



