
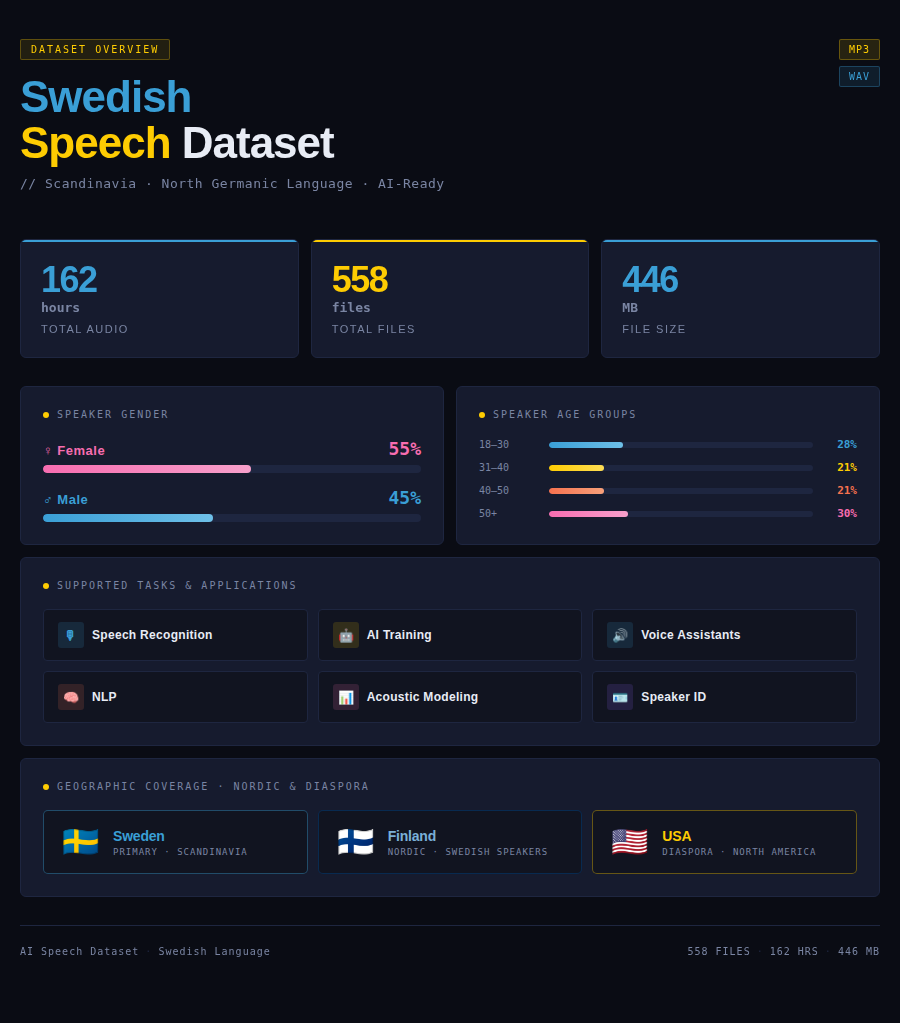
The Swedish Speech Dataset provides an extensive repository of authentic audio recordings from native Swedish speakers across Sweden, Finland, and USA diaspora. This specialized linguistic resource contains 162 hours of professionally recorded Swedish speech accurately annotated for sophisticated machine learning tasks. Swedish, spoken by over 10 million people as official language of Sweden and co-official in Finland, is documented with distinctive North Germanic phonetic characteristics essential for building effective speech recognition systems.
Audio Sample
Dataset General Info
| Parameter | Details |
|---|---|
| Size | 162 hours |
| Format | MP3/WAV |
| Tasks | Speech recognition, AI training, voice assistant development, natural language processing, acoustic modeling, speaker identification |
| File size | 446 MB |
| Number of files | 558 files |
| Gender of speakers | Female: 55%, Male: 45% |
| Age of speakers | 18-30 years: 28%, 31-40 years: 21%, 40-50 years: 21%, 50+ years: 30% |
| Countries | Sweden, Finland, USA |
Use Cases
Nordic Digital Services
Swedish government agencies can utilize the Swedish Speech Dataset to develop voice-enabled e-government services, digital public platforms, and citizen communication systems. Voice interfaces make Swedish public sector services accessible through natural language, support digital transformation of Swedish society, enable voice-based welfare state service delivery, and facilitate citizen engagement. Applications include Skatteverket (tax) services, healthcare portals, education platforms, Försäkringskassan (social insurance), and municipal services serving Sweden’s population.
Business and Innovation Sector
Swedish businesses and technology companies can leverage this dataset to create voice-enabled enterprise applications, customer service automation, and innovation platforms. Voice technology supports Swedish business sector known for innovation, enables Swedish-language business intelligence tools, positions Sweden competitively in Nordic markets, and facilitates voice commerce. Applications include business communication platforms, customer service automation for companies like Spotify and Klarna, voice-enabled CRM systems, and enterprise productivity tools.
Finland Swedish Services
Organizations serving Swedish-speaking population in Finland can employ this dataset to build bilingual services, minority language platforms, and Swedish-Finnish community tools. Voice technology supports Finland Swedish linguistic rights as co-official language, enables services for Swedish-speaking Finns, facilitates bilingual education, and maintains Swedish linguistic presence in Finland. Applications include minority language education, Swedish-language government services in Finland, cultural platforms, and broadcasting services serving Finland’s Swedish-speaking population maintaining Nordic linguistic connections.
FAQ
Q: What is included in this dataset?
A: The dataset includes 162 hours of audio recordings with 558 files totaling 446 MB, complete with transcriptions and linguistic annotations.
Q: How diverse is the speaker demographic?
A: Features 55% female and 45% male speakers across age groups: 28% (18-30), 21% (31-40), 21% (40-50), 30% (50+).
How to Use the Speech Dataset
Step 1: Dataset Acquisition – Download the dataset package from the provided link upon purchase.
Step 2: Extract and Organize – Extract to your storage and review the structured folder organization.
Step 3: Environment Setup – Install ML framework dependencies and audio processing libraries.
Step 4: Data Preprocessing – Load audio files and apply preprocessing steps like resampling and feature extraction.
Step 5: Model Training – Split into training/validation/test sets and train your model.
Step 6: Evaluation and Fine-tuning – Evaluate performance and iterate on architecture.
Step 7: Deployment – Export and integrate your trained model into production systems.
For comprehensive documentation, refer to included guides.



